[IA] Tuto stable diffusion sur son propre PC ! (2025)

Bonjour l'élite 
Y'a deux ans j'avais fait un topic qui avait eu son petit succès sur comment installer et se servir de stable diffusion https://www.jeuxvideo.com/forums/42-51-72053183-1-0-1-0-ia-tuto-installer-utiliser-stable-diffusion-pour-generer-des-images.htm
De temps en temps le topic se fait up mais les choses ont un peu évolués depuis. J'me suis dit que ça serait sympa d'update tout ça.
Fini les images dégueu sur le lien de l'ancien topic avec des mains à douze doigts, aujourd'hui on fait des trucs comme ça ->












J'vais tâcher d'être très clair dans mes explications pour rendre le topic accessible à n'importe qui.
 On va faire ça en plusieurs étapes.
On va faire ça en plusieurs étapes. _.gif ":d)") Déjà, c'est quoi stable diffusion ?
Déjà, c'est quoi stable diffusion ?
Osef, y'a ChatGPT qui fait aussi des images non ?
Seulement c'est limité à trois images par jour pour les utilisateurs gratuits. Et ce n'est évidemment pas compatible avec le NSFW... 
Faut un gros PC pour faire tourner ça ?
Une RTX 3060 vous êtes pas mal par exemple. Une GTX1070 ça fonctionne aussi, bien qu'un peu lent. Une RTX 4090 et vous êtes royal 
Pour le reste, osef du CPU et 16/32gb de ram c'est très bien. (Dans l'absolu, on peut se servir de stable diffusion avec une plus petite carte graphique, mais ce sera vraiment lent et vite limitée en terme de qualité/résolution etc... Une 1060, allez vous pourrez tester le truc, mais ça va vous saouler.)
_
Pour ceux qui ont une carte graphique AMD la méthode d'installation sera différente. Flemme de développer ce point pour vous, c'est pas sorcier mais faudra faire quelques petites manips en installant python/git, allez lire ça https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-AMD-GPUs
Faut installer un logiciel pour s'amuser là-dessus ?
Enfin si, faut bien télécharger le programme sur son PC... Mais fini l'installation casse couille, maintenant vous avez une version portable prête à l'emploi. Vous avez plus qu'à y ajouter le "modèle stable diffusion" de votre choix car il en existe plein mais je vous en conseillerai un plus bas.
Y'a aussi des sites qui proposent de se servir de stable diffusion mais c'est souvent plus restrictif qu'une installation sur son propre PC. Et parfois payant aussi. Le plus sympa à utiliser est civitai, car c'est la plus grosse base de données sur stable diffusion où tout le monde vient pour partager ses trucs. Vous avez accès de façon très simple à tout le contenu, tous les modèles etc... dans une interface très simple d'accès.
C'est quoi le délire des "modèles" ? C'est pas inclus dans le logiciel ?
Le modèle d'ia c'est la version de stable diffusion que vous allez utiliser. Y'a plusieurs versions officiels, et des milliers de variantes proposés par la commu pour affiner le modèle et le spécialiser en l'occurrence dans le style anime.
En gros c'est juste un fichier à DL et à foutre dans votre dossier.
_
L'interface, grossièrement c'est le logiciel en lui-même. Il contient tout pour faire fonctionner l'ia... sauf le modèle du coup.
Le délire de l'interface c'est qu'en fait, lorsque vous la lancez, ça va pas ouvrir un logiciel classique mais en réalité un programme python autonome qui lui va ouvrir une interface sur google chrome par la suite. Ca va bosser en arrière plan sur le programme python et créer une URL local qui va s'ouvrir toute seule dans votre navigateur internet. Vous vous amuserez donc sur cette page google qui n'est pas un vrai site mais juste un accès bien foutu à votre propre programme.
_
A savoir qu'il existe plusieurs interfaces, mais la plus connu reste Automatic1111 abrégée en A1111. Il existe une version non officiel appelée reforge, basée sur a1111 mais censé un peu mieux optimiser les perfs de votre carte graphique. Moi je vous conseille A1111 pour débuter car reforge n'a pas de version portable, lui faut l'installer avec quelques petites manips supplémentaires.
Egalement, le plus gros concurrent à A1111 est ComfyUi, c'est une interface plus complexe à utiliser, vraiment pas user friendly, mais très populaire car permet de toucher de nombreux paramètres en profondeur et propose de nombreuses choses dans toutes sortes de domaines. J'en parle pas ici mais il existe même depuis peu des modèles pour faire des vidéos, et ceux-ci sont uniquement compatible avec ComfyUi.
_
_
Concernant les modèles, comme je disais y'a quelques modèles officiels et des milliers de variantes. Pourquoi ?
Les modèles officiels sont faits par la boite derrière stable diffusion, mais de base ils sont pas fou pour faire de l'anime. Mais comme comme ils sont déjà bien complets et performants malgré tout, que la base technique est là quoi, bah les gens on pu les prendre comme "base" et les compléter pour poursuivre leurs formations et les rendre capables de faire de l'anime et même du NSFW 
_
Ça reste complexe et couteux à faire, mais des gens l'ont fait. Du coup, lorsque vous verrez un modèle anime sur internet, vous verrez comme information son "modèle de base". Car selon le modèle de base, la qualité et les fonctionnalités ne seront pas les mêmes.
Pour l'histoire on a eu :
-SD1.4 puis très vite 1.5, qui lui était le premier modèle largement adopté sur lequel on a eu la première grosse variante anime par la commu, c'est NovelAI qui était derrière ça et le modèle était abrégé NAI mais les gens continuaient de le nommer "1.5" comme le modèle de base tout simplement. Grosse grosse hype y'a deux ans de ça c'était dingue et ça tournait sur des petits PC en plus.
_
-Ensuite SD2 et 2.1, ça a fait un bide c'était osef.
_
-SDXL est venu après, grosse évolution. Le modèle était plus gourmand pour les cartes graphiques mais plus performant et entrainée sur des images plus nettes et nombres, de quoi faire des trucs plus qualitatifs.
SDXL a eu le droit à deux grosses variantes animes, celle que l'on nomme "Pony" et l'autre "Illustrious". Les deux sont très sympa et sont encore celles que l'on utilise aujourd'hui. Illustrious est plus récent et un peu plus qualitatif, c'est vraiment le dernier en date que les gens utilisent à l'heure actuelle.
Y'a aussi NoobAi, qui lui-aussi est une grosse variante de SDXL mais en reprenant également le taf d'illustrious et est censé l'amélioré... Mais c'est plus compliqué que ça et ça n'a pas autant de succès qu'illustrious, donc on va l'oublier.
_
-SD3.0 qui a bidé et SD3.5, qui est franchement sympathique et encore plus performant mais la hype n'a pas pris non plus. Y'a pas eu de gros peaufinage par la commu pour faire de l'anime là-dessus. (peut-être à cause des licences commerciales, genre moins permissif pour se l'accaparer et faire du biz dessus
ce qui fait que les célestins friqués n'ont pas pris la peine de bosser dessus pour nous pondre une grosse variante anime ? J'en sais rien)
_
-Et enfin flux, qui n'a pas été produit par l'équipe officiel mais par des anciens devs derrière stable diffusion, enfin osef c'est pareil. C'est un modèle très performant et impressionnant, rivalisant avec des gros concurrents privés en ligne comme midjourney. Bien qu'étant le plus récent il n'est pas le plus populaire car très gourmand niveau carte graphique et surtout spécialisé dans le réaliste et y'a toujours pas eu de grosse variante anime proposée par la commu.
_
-Y'a d'autres modèles officiels mais qui sont sans importances, les plus importants à retenir sont 1.5, SDXL et flux. Et plus particulièrement Illustrious, qui est basé sur SDXL.
_
Pony et Illustrious, bien que basés sur SDXL, peuvent être considérés comme de nouveaux modèles de base. (tout comme NAI était considéré comme nouveau modèle de base à l'époque pour SD1.5)
On peut voir des milliers de petites variantes sur internet mais c'est grossièrement des petits peaufinages, la base restera pony ou illustrious malgré tout. C'est important de le savoir, car selon le modèle de base les fonctionnalités peuvent changer. Vous pourrez pas utiliser sur illustrious une option conçu pour pony, et vice versa. Par contre une option conçu pour Pony, bah vous pourrez l'utiliser sur les milliers de nouveaux modèles qui prennent Pony comme base, ça restera compatible.
Ok, je prends l'interface et le modèle où ?
(pour les RTX5000 si la méthode traditionnelle ne fonctionne pas y'a une variante tout aussi simple exprès pour vous sur le github)
_
Pour le modèle on va prendre la dernière version de "WAI-NSFW-illustrious-SDXL" qui est l'un des plus populaires à l'heure où j'écrit https://civitai.com/models/827184?modelVersionId=1490781
C'est donc un modèle qui se base sur illustrious, lui-même basé sur SDXL.
_
Vous extrayez l'archive sd.webui.zip quelque part, là il pèse pas lourd mais lors du premier lancement il téléchargera tout seul ce dont il a besoin pour faire fonctionner l'ia. À terme ça pèsera donc quelques petits gigas. Vous mettez le modèle illustrious ici \sd.webui\webui\models\Stable-diffusion\ et vous lancez update.bat, ça va mettre à jour a1111. Puis vous lancez run.bat.
Le premier lancement de run.bat sera plus long car il téléchargera à ce moment là les trucs dont il a besoin, l'archive n'est volontairement pas complète pour rester légère.
Une fois fini il ouvrira tout seul l'URL de l'interface sur votre navigateur internet. À l'avenir lorsque vous lancerez run.bat pour démarrer l'ia ce sera plus rapide vous inquiétez pas 
C'est prêt à l'emploi 
Quoi faire pour débuter et faire mes premières images ?
Tout en haut à gauche vous avez un menu déroulant qui se nomme Stable Diffusion checkpoint pour choisir votre modèle, s'il est pas sélectionné par défaut vous pouvez choisir celui qu'on a pris tout à l'heure. À sa droite y'a SD VAE, vous pouvez laisser sur automatic car ce truc est intégré au modèle que vous avez pris.
_
Vous avez une case prompt et une case negative prompt, les prompts c'est la description de votre image et les negative prompt c'est des détails que vous ne voulez pas voir. C'est optionnel mais généralement on y fout des trucs de bases du genre "bad quality,worst quality,worst detail,sketch,censor", copiez/collez ce prompt négatif dans un premier temps 
Sachez également que pour écrire le prompt d'une image, on écrit pas une phrase comme sur chatgpt mais en réalité une successions de tags. C'est comme ça que stable diffusion fonctionne, même si illustrious est censé comprendre un peu les vrais phrases humaines mais il fonctionne mieux sur le systèmes de tags. Les tags sont inspirés sur le site danbooru pour info, mais sinon ça donne des prompts dans ce délire là : "masterpiece, best quality, 1girl, long hair, blond hair, blue eyes, smile, blush, red dress, black heel, standing, arms behind back, outdoors, path in a park, tree, full_shot, front view"
En gros une meuf avec des cheveux blonds et des yeux bleus dehors dans un parc.
_
Width et Height correspondent à la résolution de l'image. De base c'est réglé sur 512x512 mais c'est trop peu avec les modèles illustrious qui fonctionnent sur une base de 1024p, mettez donc 1024x1024 ou alors des formats portraits/paysages qui respectent le ratio genre 832p sur 1280p.
Batch count c'est le nombre d'images que vous allez générer en cliquant sur Generate, si vous voulez en faire plusieurs d'un coup... (Batch size c'est pareil mais ça fonctionne différemment, contentez vous de Batch count).
Sampling steps c'est le nombre de fois que l'ia va travailler l'image avant de la pondre, mettez 25 ou 30 steps c'est pas mal. Trop ou pas assez ça peut faire partir l'image en couille.
Sampling method c'est la méthode que l'ia applique pour travailler les steps. Pas besoin de savoir comment ça fonctionne, choisissez simplement "Euler A" (il est peut-être choisi de base je sais plus) qui fonctionnera bien avec votre modèle.
CFG Scale c'est en gros la fidélité que l'ia va appliqué à votre prompt. Plus c'est haut plus l'ia tente d'être fidèle, plus c'est bas plus elle peut diverger. Dans les faits on s'en rend pas trop compte ahi, mettez le à 6 ce sera bien.
Seed c'est un numéro propre à l'image. Faites deux images avec les mêmes paramètres mais deux seeds différentes, les deux seeds offriront deux images différentes. Laissez le sur -1, ça signifie une seed aléatoire à chaque nouvelle image.
hires.fix si vous voulez upscale l'image en la générant dans une plus haute résolution. Un poil plus technique et peut faire partir l'image en couille en plus d'être beaucoup plus lent à générer mais en gros mettez Denoising strength sur 0.45, Hires steps sur 20, l'upscaler sur "R-ESRGAN 4x+ Anime6B" (perso j'utilise 4x_foolhardy_Remacri https://openmodeldb.info/models/4x-Remacri qui n'est pas inclus de base, faut l'ajouter dans \stable-diffusion-webui-reForge\models\ESRGAN\) et Upscale by sur 1.5 voir 2.
Les bases sont là 
Je galère un peu, mes images sont dégueu. Je peux pas choper une belle image déjà faite par quelqu'un d'autre et la reproduire facilement ?
Pour ça il faut que les metadonnées de l'image soient encore présentes, mais sur civitai c'est souvent le cas. Prenez une image dont les infos sont visibles, téléchargez là et foutez là dans cet onglet. Il proposera un bouton "send to txt2img" qui va appliquer les prompts/paramètres de l'image pour que vous puissiez générer la même image à votre tour
Alors ce sera jamais exactement la même image, y'a toujours un détail qui diffère d'un PC à l'autre... Mais vous pourrez refaire la même chose dans l'idée quoi.
Par contre, si l'image utilisait un lora ou un autre modèle que vous n'avez pas, là forcément vous aurez du mal à faire pareil. Mais tentez quand-même, vous aurez des images sympa grâce à ce que les autres partagent. Puis au pire rajoutez vous les loras en question.
Je peux reproduire fidèlement un vrai personnage d'anime ?


En gros, faut rajouter un petit fichier dans votre dossier \stable-diffusion-webui\models\Lora\. Le lora est entrainé pour reconnaitre le personnage en question et aidera l'ia à le reproduire dans votre image. Voyez ça comme un mini modèle qui vient s'additionner votre vrai modèle genre illustrious.
_
Par exemple ce lora là https://civitai.com/models/1292507/tsukasa-yuzaki-tonikaku-kawaii-lora-illustrious Sans lui l'ia galère a reproduire la meuf, là c'est nickel.
A savoir que chaque lora est conçu pour un type de modèle, soit illustrious soit pony etc... Vous avez compris.
Si vous vous prenez au jeu y'a des tonnes d'extensions à rajouter à A1111 qui rajoutent de nouvelles options...
Quand vous installez une extension, allez dans Installed puis cliquez sur Apply and Restart UI pour qu'elle s'ajoute correctement.
_ Perso j'utilise SD WebUI Tag Autocomplete https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
Qui affiche des suggestions de tags pour compléter votre mot lorsque vous êtes en train d'écrire. Il connait tous les tags de danbooru donc c'est ultra pratique. SD webui Infinite Image Browsing https://github.com/zanllp/sd-webui-infinite-image-browsing
Qui rajoute un onglet avec un exploreur d'images pour voir directement dans a1111 toutes vos anciennes générations avec leurs prompts etc... SD webui prompt all in one https://github.com/Physton/sd-webui-prompt-all-in-one
Qui rajoute un menu très pratique sous les cases des prompts et negatives prompts. Ça illustre vos prompts en mettant les tags dans des petites cases pour réorganiser tout ça très facilement sans retoucher au clavier. Ça propose aussi d'autres options sympa pour vos prompts.
_
Y'a plein d'autres trucs, controlnet pour contrôler précisément la position du personnage ou d'autres éléments de l'image, regional prompter pour écrire des prompts différents selon la zone de l'image, wildcards pour insérer plusieurs tags dans une "carte" qui s'ajoute aux prompts pour que l'ia choisisse un tag au hasard dans cette carte à chaque nouvelle image et avoir de la variété lorsque vous faites plusieurs images d'un coup... Y'a plein d'extensions sympa.
Y'a un site qui réuni tout le contenu lié à stable diffusion ?
C'est la référence pour regarder/partager/télécharger tout ce qui est lié à stable diffusion. Les derniers modèles, les images que font les gens, tout est là-bas. Vous pouvez même générer des images avec leur système mis en place moyennant quelques buzz, la monnaie du site. C'est payant mais y'a moyen d'en avoir quelques uns gratuit en réagissant aux images, en partageant du contenu...
On est reparti pour deux ans 
J'fais pas ça pour faire de la pub mais c'est quand-même intéressant à dire, y'a un serveur discord d'ia entre clés. Si vous voulez le rejoindre pour causer ia ou voir ce que les autres disent/partagent hésitez pas 
Mais bien sûr vous pouvez causer et poser vos questions sur le topic, c'est là pour ça



J'avais réussi à installer Stable Diffusion, le lancer et tout en utilisant Stability Matrix... Et je n'ai jamais réussi à créer une image... 
Ça moulinait pendant de longues minutes puis rien ne s'affichait
Le 02 avril 2025 à 10:39:31 :
Merci je fav pour lire ça à tête reposée delete pas stp
T'inquiètes, si t'as un souci tu repasses ici 



Le 02 avril 2025 à 10:41:31 :
Ça a pas mal changé depuis la dernière dois où j'avais essayé ce truc
Comparé à y'a deux ans quand la hype prenait c'est clairement un autre délire 
Le 02 avril 2025 à 10:42:06 :
J'avais réussi à installer Stable Diffusion, le lancer et tout en utilisant Stability Matrix... Et je n'ai jamais réussi à créer une image...
Ça moulinait pendant de longues minutes puis rien ne s'affichait
Chelou. J'ai jamais essayé cette interface, mais tente avec celle de mon tuto. On utilise plutôt automatic1111 qui est la référence pour stable diffusion
Le 02 avril 2025 à 10:43:33 :
1,6 Go de Vram, je risque d'abimer mon pc si j'essaye ?
Même pas la peine d'essayer ahi. Après on peut faire bosser son CPU à la place mais même avec un bon modèle ce sera très lent 
Le 02 avril 2025 à 10:46:58 :
Ça moulinait pendant de longues minutes puis rien ne s'affichait
Chelou. J'ai jamais essayé cette interface, mais tente avec celle de mon tuto. On utilise plutôt automatic1111 qui est la référence pour stable diffusion
C'est possible que ce soit ç cause du PC s'il n'est pas assez puissant ?
Tu peux nous donner un exemple de prompt complet pour voir la complexité ?
Le 02 avril 2025 à 10:46:50 :
Genial maintenant que j'ai un PC puissant je voulais tester. Et pour générer des images très réalistes, pas NSFW mais pour illustrer des vidéos c'est quoi les meilleurs modèles ?
Pour faire des images réalistes en local c'est flux le meilleur modèle. Mais par contre il fonctionne pas sur l'interface a1111, faut soit passer par reforge soit par ComfyUI



Le 02 avril 2025 à 10:54:45 1MinutePasPlus a écrit :
C'est payant je suppose ? Il faut un abonnement ?
Non c'est gratuit, mais vaut mieux avoir un pc un minimum puissant, surtout au niveau GPU.
Le 02 avril 2025 à 10:51:59 :
ça fait 2 ans que je fais m'umuse avec, j'utilise ponyxl en ce moment
T'as essayé illustrious ? Dans l'ensemble c'est plus sympa que Pony
Le 02 avril 2025 à 10:54:45 :
C'est payant je suppose ? Il faut un abonnement ?
Complètement gratuit et open source. T'installes ça sur ton PC et tu t'amuses
Le 02 avril 2025 à 11:08:16 :
Pourquoi avoir besoin d'un pc puissant si on entraîne pas le model ?
_.gif ":)")
Faut quand-même un PC qui tient la route pour le faire tourner, c'est pas rien non plus
Le 02 avril 2025 à 10:49:14 :
Le 02 avril 2025 à 10:46:58 :
Ça moulinait pendant de longues minutes puis rien ne s'affichait
Chelou. J'ai jamais essayé cette interface, mais tente avec celle de mon tuto. On utilise plutôt automatic1111 qui est la référence pour stable diffusion
C'est possible que ce soit ç cause du PC s'il n'est pas assez puissant ?
Tu peux nous donner un exemple de prompt complet pour voir la complexité ?
T'as quoi comme PC ?
Une carte graphique trop petite et l'image peut ne pas vouloir se générer ouais.
Une image exemple avec son prompt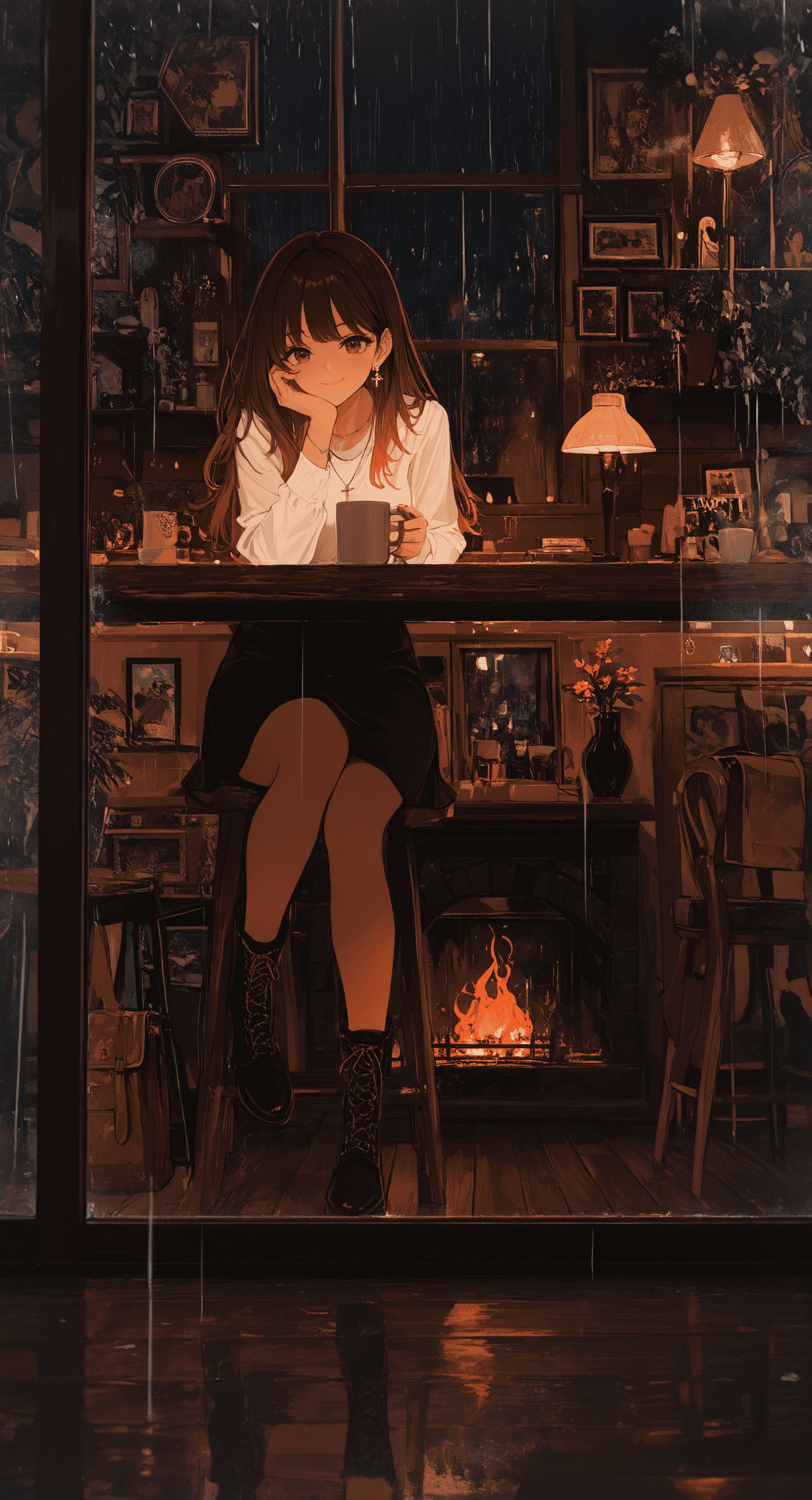 masterpiece, best quality, good quality, very awa, newest, highres, absurdres, 1girl, solo, long hair, looking at viewer, smile, shirt, skirt, brown hair, long sleeves, holding, closed mouth, jewelry, sitting, brown eyes, white shirt, full body, flower, earrings, boots, indoors, black skirt, black footwear, necklace, bag, cup, window, night, brown footwear, chair, table, plant, fire, holding cup, steam, hand on own face, cross-laced footwear, reflection, rain, head rest, wooden floor, mug, hand on own cheek, potted plant, lamp, hand on own chin, stool, coffee, picture frame, vase, coffee mug, drawing \(object\), cafe, wooden table, fireplace, limited palette
masterpiece, best quality, good quality, very awa, newest, highres, absurdres, 1girl, solo, long hair, looking at viewer, smile, shirt, skirt, brown hair, long sleeves, holding, closed mouth, jewelry, sitting, brown eyes, white shirt, full body, flower, earrings, boots, indoors, black skirt, black footwear, necklace, bag, cup, window, night, brown footwear, chair, table, plant, fire, holding cup, steam, hand on own face, cross-laced footwear, reflection, rain, head rest, wooden floor, mug, hand on own cheek, potted plant, lamp, hand on own chin, stool, coffee, picture frame, vase, coffee mug, drawing \(object\), cafe, wooden table, fireplace, limited palette
Mais y'a des loras, t'auras pas une image aussi bonne en recopiant bêtement le prompt. Sinon pour faire un essai plus simple, tente un truc comme ça :
Prompt : masterpiece, best quality, 1girl, long hair, blond hair, blue eyes, smile, blush, red dress, black heel, standing, arms behind back, outdoors, path in a park, tree, full_shot, front view
Prompt négatif : bad quality,worst quality,worst detail,sketch,censor




Merci pour ton partage l'op
J'ai supprimé stable diffusion à cause du temps que ça prenais avec ma pauvre RX 6600, je m'y remettrai quand je changerai de CG 
Le 02 avril 2025 à 11:15:49 :
automatic1111 alors que reforge existe
Perso j'utilise reforge ouais mais faut installer python et git soi-même, a1111 en plus d'être la référence de base est bien plus accessible avec sa version portable sans prérequis. C'est le choix le plus logique à prendre pour débuter
Le 02 avril 2025 à 11:17:17 :
Merci pour ton partage l'opJ'ai supprimé stable diffusion à cause du temps que ça prenais avec ma pauvre RX 6600, je m'y remettrai quand je changerai de CG

Ça marche
Le 02 avril 2025 à 11:12:48 KillerJamme a écrit :
Le 02 avril 2025 à 10:51:59 :
ça fait 2 ans que je fais m'umuse avec, j'utilise ponyxl en ce momentT'as essayé illustrious ? Dans l'ensemble c'est plus sympa que Pony

Le 02 avril 2025 à 10:54:45 :
C'est payant je suppose ? Il faut un abonnement ?Complètement gratuit et open source. T'installes ça sur ton PC et tu t'amuses
Le 02 avril 2025 à 11:08:16 :
Pourquoi avoir besoin d'un pc puissant si on entraîne pas le model ?Faut quand-même un PC qui tient la route pour le faire tourner, c'est pas rien non plus
Le 02 avril 2025 à 10:49:14 :
Le 02 avril 2025 à 10:46:58 :
Ça moulinait pendant de longues minutes puis rien ne s'affichait
Chelou. J'ai jamais essayé cette interface, mais tente avec celle de mon tuto. On utilise plutôt automatic1111 qui est la référence pour stable diffusion
C'est possible que ce soit ç cause du PC s'il n'est pas assez puissant ?
Tu peux nous donner un exemple de prompt complet pour voir la complexité ?
T'as quoi comme PC ?
Une carte graphique trop petite et l'image peut ne pas vouloir se générer ouais.
Une image exemple avec son promptmasterpiece, best quality, good quality, very awa, newest, highres, absurdres, 1girl, solo, long hair, looking at viewer, smile, shirt, skirt, brown hair, long sleeves, holding, closed mouth, jewelry, sitting, brown eyes, white shirt, full body, flower, earrings, boots, indoors, black skirt, black footwear, necklace, bag, cup, window, night, brown footwear, chair, table, plant, fire, holding cup, steam, hand on own face, cross-laced footwear, reflection, rain, head rest, wooden floor, mug, hand on own cheek, potted plant, lamp, hand on own chin, stool, coffee, picture frame, vase, coffee mug, drawing \(object\), cafe, wooden table, fireplace, limited palette
Mais y'a des loras, t'auras pas une image aussi bonne en recopiant bêtement le prompt. Sinon pour faire un essai plus simple, tente un truc comme ça :Prompt : masterpiece, best quality, 1girl, long hair, blond hair, blue eyes, smile, blush, red dress, black heel, standing, arms behind back, outdoors, path in a park, tree, full_shot, front view
Prompt négatif : bad quality,worst quality,worst detail,sketch,censor
Nan pas test, mais je testerai ça merci
J'ai tenté d'utiliser Hunyuan Video, mais vu que j'ai une 7900 xt et donc pas de greedvidia, bah c'est compliqué (ça marche pas), peut être que maintenant il y a les supports pour mais bon.
J'utilise Rocm d'AMD pour générer.
Données du topic
- Auteur
- KillerJamme
- Date de création
- 2 avril 2025 à 10:38:14
- Nb. messages archivés
- 416
- Nb. messages JVC
- 410
JvArchive compagnon