[ALERTE] OpenAI annonce o1 : le GRAND REMPLACEMENT ARRIVE
SuppriméLe 12 septembre 2024 à 20:25:34 :
Je viens de tester, je suis très sceptique.Il sait enfin faire des calculs de maths, mais ne présente plus la démonstration (ou alors faut le préciser dans le prompt, la ou a l’époque on le faisait spontanément).
chez moi il s'est déjà planté dans des calculs 
Le 12 septembre 2024 à 20:29:29 :
Le 12 septembre 2024 à 20:28:26 :
Le 12 septembre 2024 à 20:26:57 :
Le 12 septembre 2024 à 20:25:34 :
Je viens de tester, je suis très sceptique.Il sait enfin faire des calculs de maths, mais ne présente plus la démonstration (ou alors faut le préciser dans le prompt, la ou a l’époque on le faisait spontanément).
Je pense effectivement que c'est une question de prompt, de toute façon j'espère que d'autres modèles vont adopter ce même paradigme et vont être moins censuré ou moralisateur
Oui, mais sur la précédente version, j’avais pas besoin de le renseigner dans le prompt.
En fait, j’ai utilisé Exactement le même prompt sur les 2 versions.
Et en plus la précédente version ne m’a pas fait de pavé moralisateur, mais une modélisation mathématique, alors que cette nouvelle version m’a fait un pavé moralisateurs à la place.
o1 cache son raisonnement interne
ça me fait penser à la prompt reflection ça (avec le scammer récemment pour ceux qui suivent l'actu LLM ), en pratique sur le papier c'est intéressant, j'ai testé avec un system prompt et 4o fait pas l'erreur de merde sur les 3 r du mot strawberry (qu'ils utilisent en exemple pour o1)
Le problème avec OpenAI c'est qu'ils sont plus très Open paradoxalement donc les papiers vont mettre du temps à venir pour que d'autres fassent des modèles axés raisonnement comme o1
Le 12 septembre 2024 à 20:32:11 :
Le 12 septembre 2024 à 20:25:34 :
Je viens de tester, je suis très sceptique.Il sait enfin faire des calculs de maths, mais ne présente plus la démonstration (ou alors faut le préciser dans le prompt, la ou a l’époque on le faisait spontanément).
chez moi il s'est déjà planté dans des calculs
Bon, après je lui ai donné un problème simple (c’est juste une histoire de puissance à faire)

J'ai regarde les videos de demonstrations et wow, c'est super impressionant!
VIvement que je me fasse remplace par une IA qui a du mal a faire un Snake ou un jeu d'arcade a la con qu'on torche rapidement 
Je suis vraiment pas impressione par ce model. J'attends d'avoir des utilisations plus concretes
Le 12 septembre 2024 à 20:29:29 :
Le 12 septembre 2024 à 20:28:26 :
Le 12 septembre 2024 à 20:26:57 :
Le 12 septembre 2024 à 20:25:34 :
Je viens de tester, je suis très sceptique.Il sait enfin faire des calculs de maths, mais ne présente plus la démonstration (ou alors faut le préciser dans le prompt, la ou a l’époque on le faisait spontanément).
Je pense effectivement que c'est une question de prompt, de toute façon j'espère que d'autres modèles vont adopter ce même paradigme et vont être moins censuré ou moralisateur
Oui, mais sur la précédente version, j’avais pas besoin de le renseigner dans le prompt.
En fait, j’ai utilisé Exactement le même prompt sur les 2 versions.
Et en plus la précédente version ne m’a pas fait de pavé moralisateur, mais une modélisation mathématique, alors que cette nouvelle version m’a fait un pavé moralisateurs à la place.
o1 cache son raisonnement interne
Alors ça ne m’intéresse pas. Je ne veux pas un résultat, mais le cheminement du raisonnement.
Le 12 septembre 2024 à 20:33:27 :
Ouais ben que l'IA trouve un remède à la maladie de Charcot et je trouverais ça pertinent et incroyable, pour l'instant c'est que du bullshit talk
ça arrive dans la recherche ne t'inquiète pas
https://arxiv.org/abs/2409.04109
à voir ce que ça donne en plus avec les nouveaux modèles
Laisse moi deviner, une ia incapable de démontrer les équations de Navier-Stokes ou autres problèmes de ce type. IA incapable de concevoir des idées.
Liste sujets, ça sert à que dalle 
Faut prendre là pour test ?
Lors de nos tests, la prochaine mise à jour a obtenu des résultats similaires à ceux d'étudiants en doctorat sur des tâches de référence difficiles en physique, en chimie et en biologie. Nous avons également constaté qu'il excelle en mathématiques et en codage. Lors d'un examen de qualification pour les Olympiades internationales de mathématiques (IMO), GPT-4o n'a résolu correctement que 13 % des problèmes, tandis que le modèle de raisonnement a obtenu un score de 83 %. Leurs capacités de codage ont été évaluées lors de concours et ont atteint le 89e percentile dans les compétitions Codeforces.
bordel de merde  les dev en sueur
les dev en sueur
Le 12 septembre 2024 à 20:34:42 :
Par contre j’ai pas cette version alors que j’ai chatgpt premium
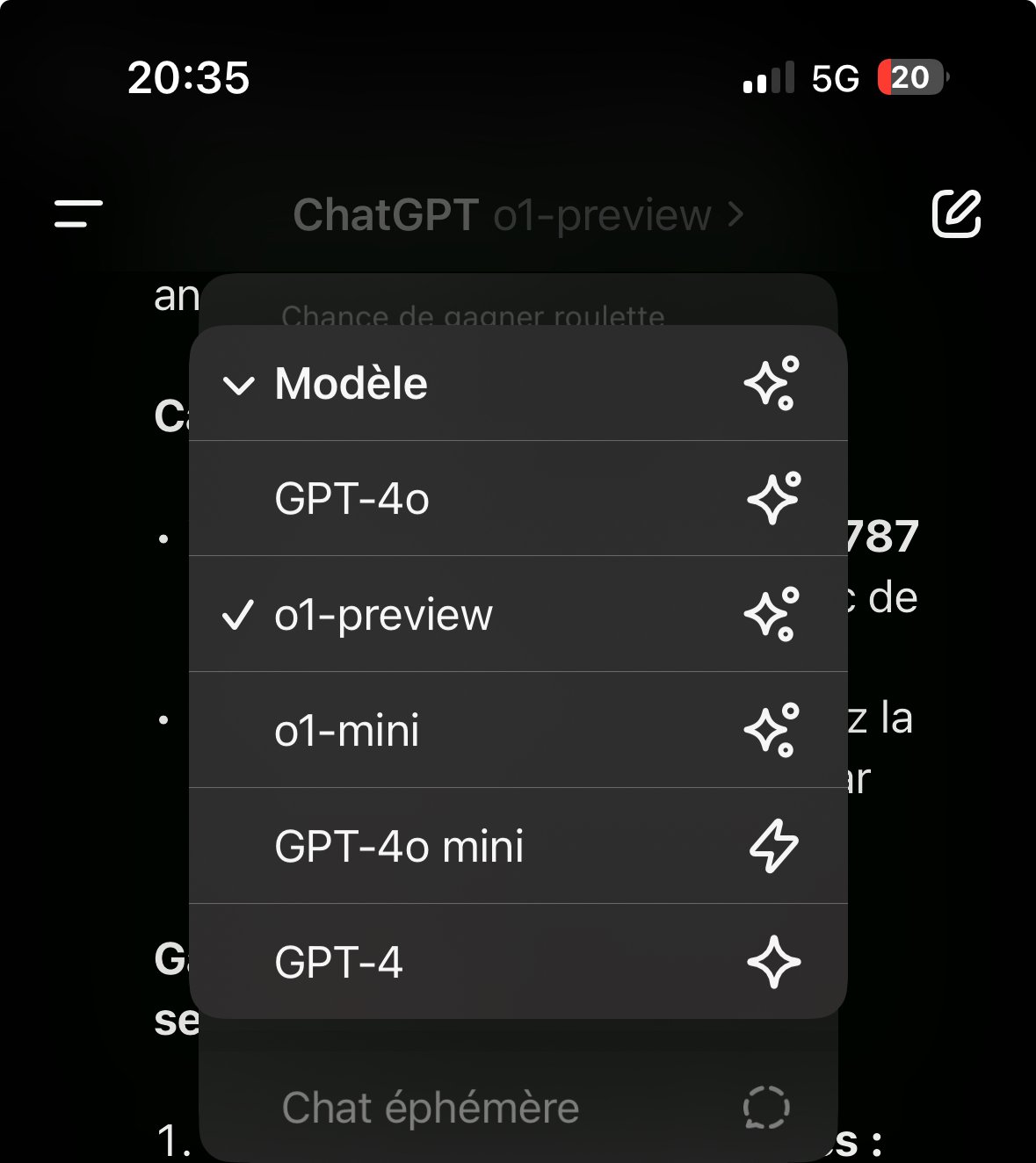
Le 12 septembre 2024 à 20:34:39 :
Faut prendre là pour test ?
Non normalement c'est comme quand tu sélectionnes un modèle entre 4o et mini
Là on dirait un "GPT" du store, je sais pas si c'est fiable

J'ai premium et :
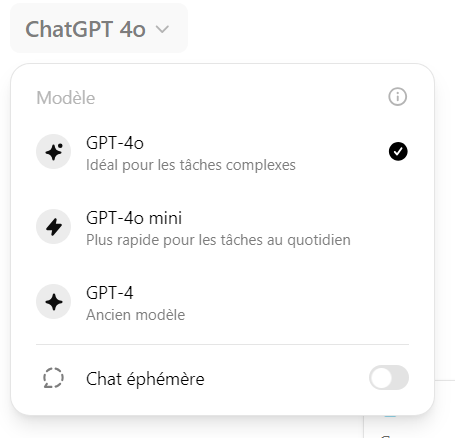
Le 12 septembre 2024 à 20:36:30 :
J'ai premium et :
Parce que c’est probablement encore en phase d’A/B testing.
Je vois même pas la.diff.entre chat gpt 3.5 et 4
Le 12 septembre 2024 à 20:16:26 :
Finito les abrutis de med g qui serviront plus à rien
L'AI qui pourra distribuer les dolipranes
Données du topic
- Auteur
- GR_PAR_IA
- Date de création
- 12 septembre 2024 à 20:06:23
- Date de suppression
- 12 septembre 2024 à 21:12:00
- Supprimé par
- Modération ou administration
- Nb. messages archivés
- 55
- Nb. messages JVC
- 58